Crawler
A crawler is an automated program that browses the web to collect data from websites. It visits pages, extracts information and follows links to discover more content, storing the data for further use.
Crawler Categorization
The crawler categorization includes reports organized according to data categories. The main objective of the crawler feature is to simplify the search process for crawled datasets by organizing them according to their category and source of retrieval. This reduces the need for redundant data collection and enhances data accessibility.
The datasets retrieved by the crawler should be systematically organized by their columns and stored in the system for efficient access and management. Users can search for crawled data based on category and source and also view the relevant columns. This structure helps users easily categorize and navigate the crawled data, streamlining the process of data retrieval and analysis.
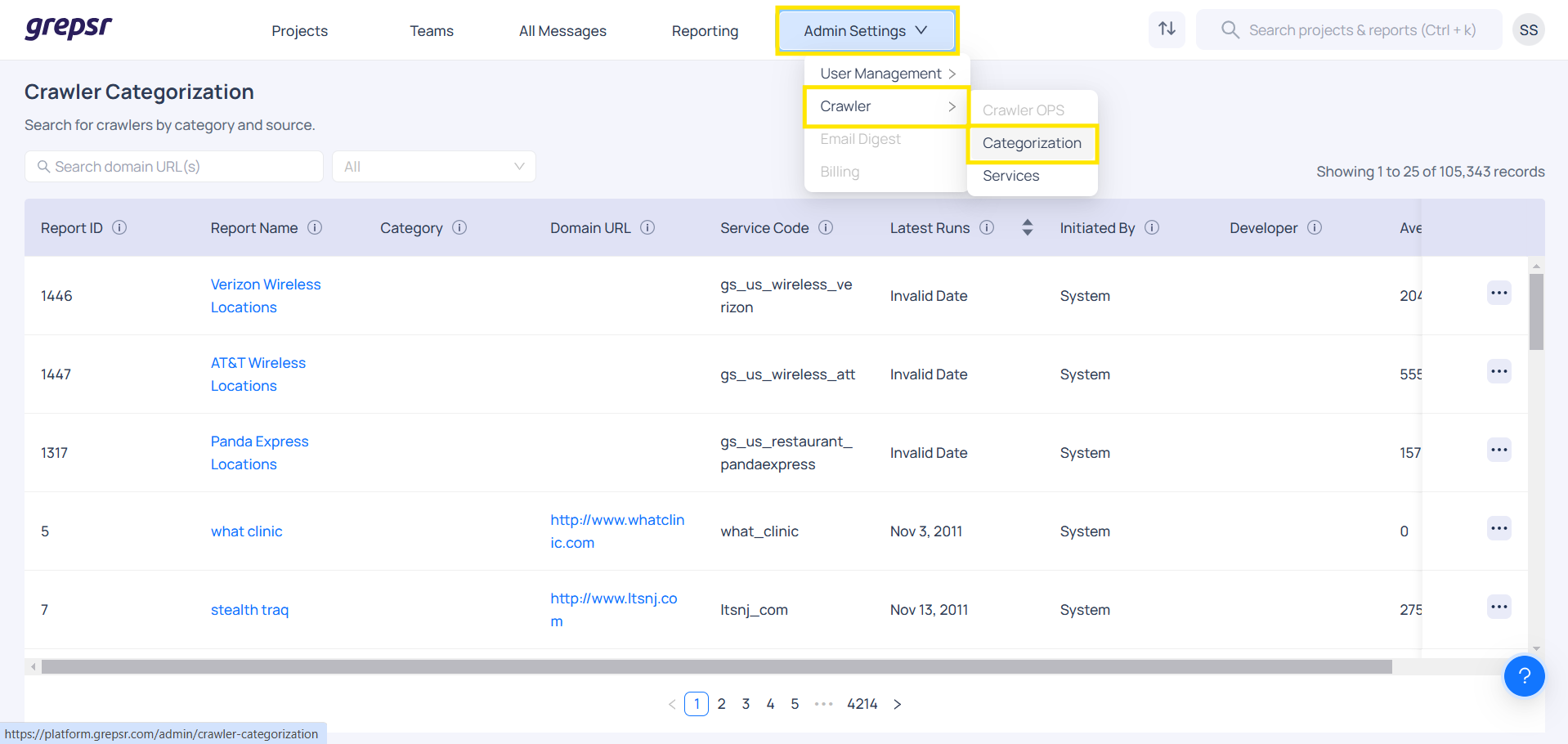
The main goal of this feature is to make it easier to search through crawled datasets by category and source, reducing the need for repeated data collection and improving data accessibility.
Key benefits
- It gives insight into the nature of the data we hold.
- It facilitates data search and sales based on the category.